

I'm currently writing a book set in 2003. This involves a fair amount of research, not just into recent history, but into the culture of the time. Which means a lot of time spent in the Wayback Machine.
Digital archiving is a difficult project, and writing this book has exposed me to some of these difficulties. Although some of the references in this post are dated, due to the focus/nature of the research I'm doing, the problems are not. I try to bring in contemporary examples to drive the point home.
Isn't the internet forever, though?
Yes and no...the internet is forever in the sense that once you put something on the internet, you have to assume that it's going to stay out there, in some form, for the rest of time. That doesn't mean it actually will be out there, though. You can't control what happens to something once you post it on the internet. Treating the web like your own private hugbox or your own public dropbox is probably not going to work out very well.
There are a lot of pages that have not been archived anywhere. Unless someone saved a copy to their hard drive, or unless you can scare up a Google cache, that old page is as gone as a burnt manuscript. Even if a million people saw the page when it was live.
Who archives the web?
I've already mentioned the Wayback Machine. There many web archiving options online, such as the Australian Government Web Archives. There are also on-demand archivers, such as Archive.is (not to be confused with Archive.org, which runs the Wayback Machine). On-demand archivers don't crawl the web, but they allow you to make copies of webpages that you specify––such as this one.
PageFreezer seems geared towards companies or professionals who want "authenticated, legally admissible, easy to produce digital evidence" from their own websites and social media accounts. It seems geared towards people who want to limit their liability from false complaints (e.g. falsified tweet screenshots), not towards preserving a public archive.
Why is digital archiving so difficult?
One problem is just the sheer enormity of the internet. There are over 4.5 billion webpages online right now. Which ones should be archived? How often? What methods should archivists use to decide which pages are worth archiving consistently? Unless an archiving website gets an enormous grant, archiving all of these pages is not realistic.
Some webpages are difficult to archive due to changing technology. How may webpages still use Realplayer clips? How many use obsolete music or video players? If SoundCloud or Spotify shuts down, many current pages will have dead links, even in the archives. Screenshots can get around some of these problems, preserving the look and feel of the page in a way that more dynamic archives can't capture (see: all the broken image links and weird formatting on Wayback Machine pages, like this one).
Any archival project is also going to run afoul of privacy concerns in some way or another. Look at the short-lived site Frienditto, which could archive private livejournal entries that their writers may not have wanted the public to see. Frienditto was an extreme case, which is probably why it was shut down so quickly. It's one thing to repeat something told in confidence, it's another to proclaim it in front of the entire world, which is what Frienditto did.
However, even a site that only archives publicly accessible pages can run afoul of privacy concerns. If people have the right to be forgotten, doesn't preserving their teenage prose poems (username available) run counter to that right? Does Lord Byron have the right to "burn his manuscripts" if they're stored across several servers in different countries? How can he prove they're his manuscripts, that "xwarriorxpoetx" is really him?
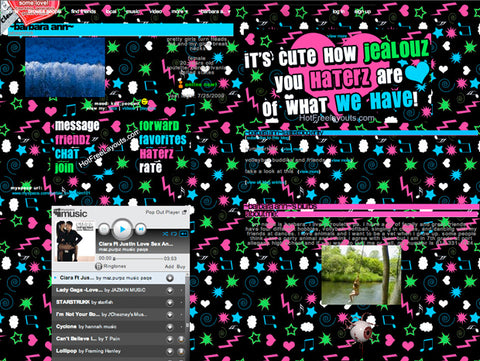
Another problem is that many webpages can go offline with no warning, making it difficult to prioritize what should and should not be archived. Myspace is an extreme example. When Myspace updated their look, they got rid of their user's journals, among other things. You can log in and read/download your own entries, but you can’t read anyone else’s. If you don't have your old email address that you used for Myspace, too bad.
The Myspace update was unexpected––not that they would reboot their look, which was a long time coming, but that they would get rid of so much content without warning.
I'm sure there are people who are not exactly broken up over that. “Oh no, no one can read the prose poems I wrote when I was seventeen”––said (almost) no one ever. But what if the account holder died? What if that journal gave other people some kind of comfort and connection to their lost son, brother, father, etc.? Unless mom/sis/widow made a backup copy herself, which she may not even know how to do, then there’s no way for her to reread those journal entries without a cache. And there is no guarantee that a cache exists, especially if only a handful of people ever visited the page.
So you can go very quickly from a webpage being accessible to the entire world, to essentially vanishing from the entire web, over a very short period of time.
If you visit the Wayback Machine, you may have trouble finding archived Myspace pages. They're not blocked by robots.txt the way Livejournals are, but many Myspace pages and journals are simply not available (unless the journal was fairly popular, e.g. Courtney Love's).
And that is what disturbs me––the ability to erase once-accessible information from the web. Many people assume that the internet is being archived consistently but it isn't. A new robots.txt file could make certain pages or entire websites inaccessible on certain archives. Even pages like this could vanish under the wrong circumstances.
A motivated company or organization can get pages pulled from the archives, even on websites they don't control. Scientology has already pressed the issue, by successfully removing certain critical webpages from the Wayback Machine.
How could archiving the internet be made easier?
On an individual level, preserving your own pages on- and off-line is a good start. It's good to make online and off-line backups of your own website, blog entries, etc. Remember that private companies like Twitter and Wordpress.com own the platform(s) that you're posting on, so multiple back-ups are the name of the game in case of some Myspace-like wipeout.
I've also gotten in the habit of archiving every page I reference in an article or essay, and including this archive in the citations, like so:
Patterson, Ti-Erika. "Do Children Just Take Their Parents' Political Beliefs? It's Not That Simple." The Atlantic, May 1, 2014. Accessed at http://www.theatlantic.com/politics/archive/2014/05/parents-political-beliefs/361462/ on 22 December 2015. Archived at: https://archive.is/feHD4
Browser extensions are another option. The archive.is button is a good examples of this. Clipular too, possibly. Browser extensions like this make it easier to archive some of the less-visited websites, blogs, and forums on the web.
As for some of the larger issues uncovered in this post, I'm afraid I don't have any easy answers, other than to keep discussing these issues. Absent public discussion (and I do mean public discussion, not just media chatter), I can see another Frienditto-like service coming along and sucking all the oxygen out of the debate.
2 comments
Johnny,
I guess it’s one of the quirks of this theme that the author isn’t shown on the actual post. Another thing to fix…
The author of this post is Elizabeth Main. Feel free to cite it as you see fit.
Thank you for your interest!
This is a really great look at one person’s exploration of the problems of assessing, funding and caring about what digital information is going to be saved for future generations, thanks.
One thing though, who has written it? I would love to cite this in a paper I am working on – but at the moment the author will be anonymous/Calhoun Press and in someways this goes to the heart of whether it will ever be possible to archive through computer algorithms that are able to approximate human curiosity and the desire to not to forget.
thanks again – great post… whoever you are.